
1. 목표: Dynamic Web도 크롤링 가능한 Web Sublink Crawler 제작
요구사항
- 불특정 다수의 웹사이트의 하위 링크를 모두 찾는다.
- SPA에도 통용되어야 한다.
- 시간이 너무 오래걸려선 안된다.
- 모듈화 가능하게 제작한다.
2. 첫 번째 시도 : SEO 크롤러 사용
Screaming frogm, Moz 등 다양한 SEO 크롤러 활용

SPA가 아닌 웹사이트의 경우 모든 하위링크를 잘 찾는 모습이다.
여기서는 대략 266개의 하위 링크를 찾았고, 시간은 대략 3분 정도가 걸렸다.
SPA의 경우는 하위링크를 잘 찾지 못하는 것으로 확인되었다.
장점 :
- 사용이 쉽다
- SPA가 아니라면 모든 링크를 잘 찾는다.
단점 :
- 유료 플랜이 있다.
- 시간이 오래걸린다.
- SPA의 경우 하위 링크를 찾지 못한다.
3. 두 번째 시도: 다양한 오픈소스 활용
3.1. golang으로 제작된 서브 도메인 스캐너 사용
GitHub - mhmdiaa/second-order: Second-order subdomain takeover scanner
Second-order subdomain takeover scanner. Contribute to mhmdiaa/second-order development by creating an account on GitHub.
github.com
위 메세지처럼 옵션을 주고 사용 가능하다.
<code />
{"LogQueries":{"https://www.banksalad.com/":{
"script[src]":["https://www.googletagmanager.com/gtag/js?id=G-JXY9T1WQ5G"
,"//t1.daumcdn.net/adfit/static/kp.js",
"https://connect.facebook.net/en_US/sdk.js",
"//developers.kakao.com/sdk/js/kakao.min.js",
"//cdn.banksalad.com/resources/protocol/protocol.min.js",
"/dist/v2.vendor.js","/dist/v2.bundle.js",
"//wcs.naver.net/wcslog.js"]
}}}
그러나 하위 링크를 찾고자 하는 상기 목적과는 다른 결과물이 나와서 폐기하였다.
3.2. 일반 크롤러 활용
https://github.com/r3dxpl0it/Damn-Small-URL-Crawler
GitHub - r3dxpl0it/Damn-Small-URL-Crawler: A Minimal Yet Powerful Crawler for Extracting all The Internal/External/Fuzz-able Lin
A Minimal Yet Powerful Crawler for Extracting all The Internal/External/Fuzz-able Links from a website - GitHub - r3dxpl0it/Damn-Small-URL-Crawler: A Minimal Yet Powerful Crawler for Extracting all...
github.com
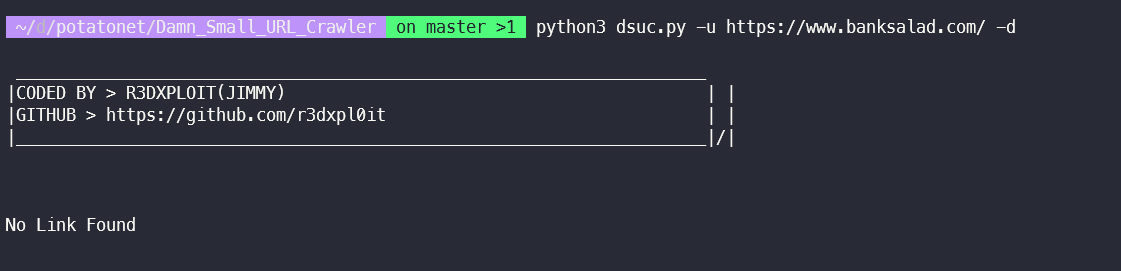
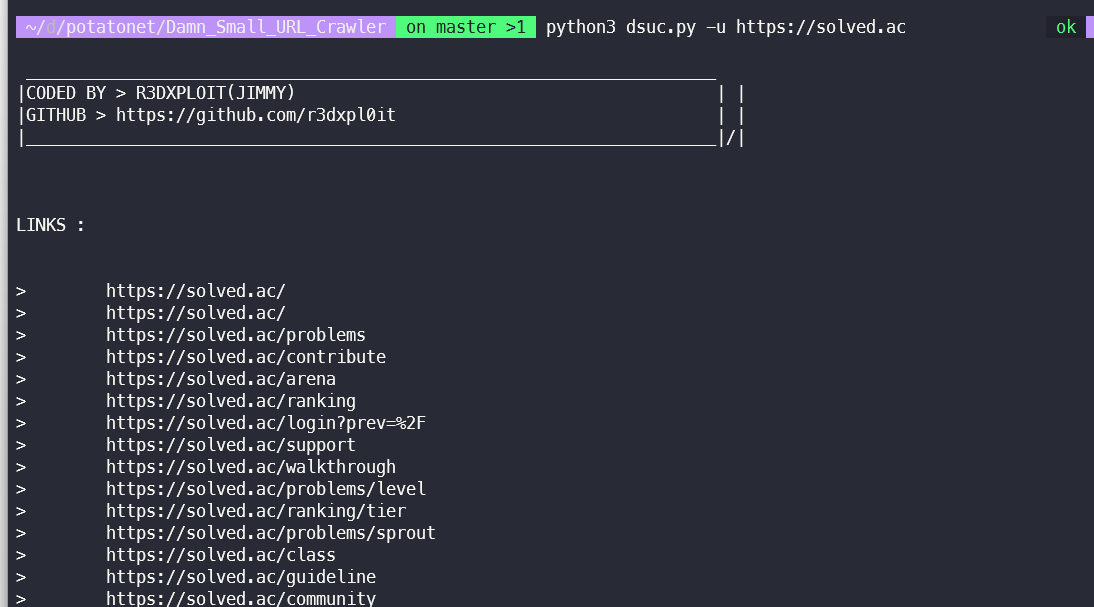
역시나 SPA가 아닐때에만 크롤링이 된다.
4. 세 번째 시도: link extractor 프로그램 사용
https://www.prepostseo.com/link-extractor
[URL Extractor Online - Extract links from website
www.prepostseo.com](https://www.prepostseo.com/link-extractor)
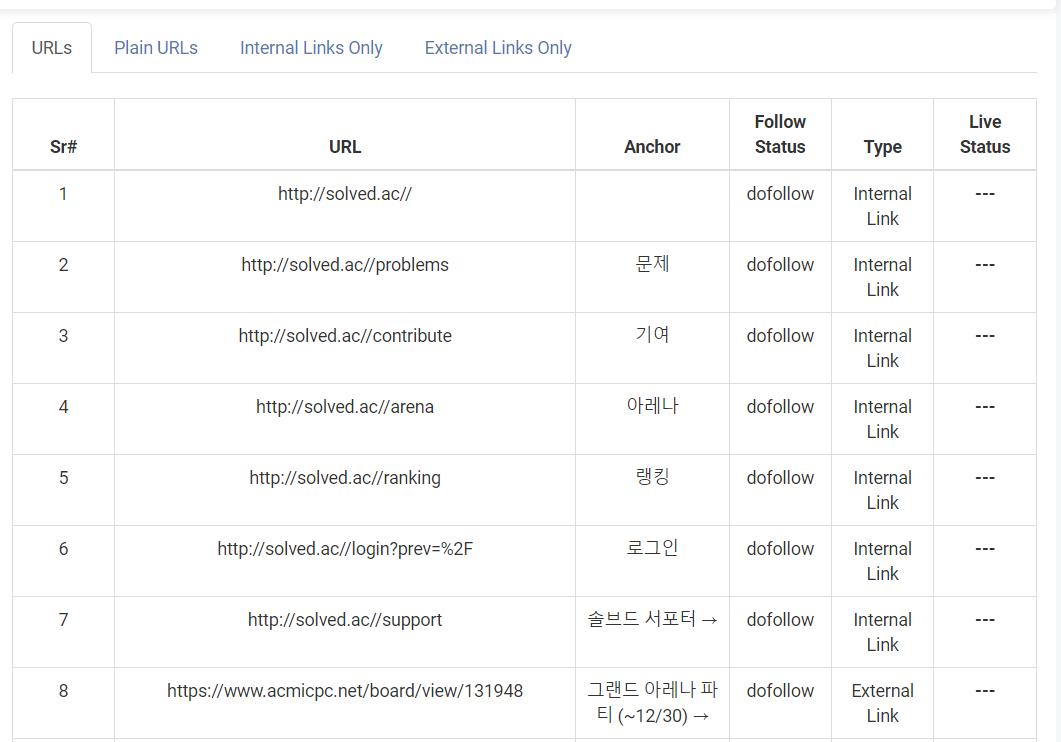
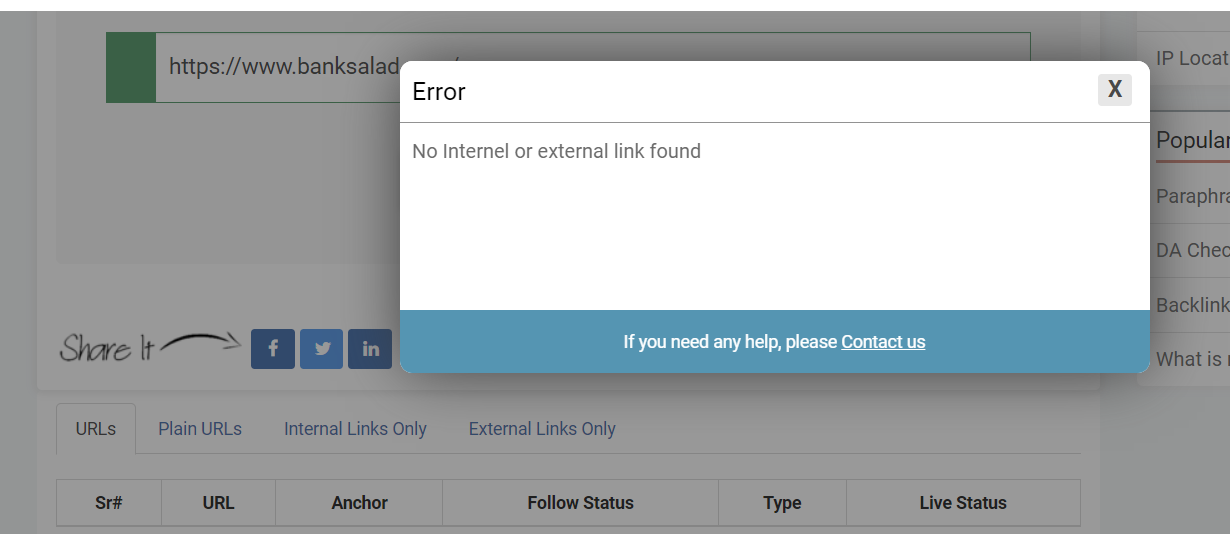
좌측: 일반 정적 웹사이트 URL을 넣었을 때
우측: 동적 웹사이트 URL을 넣었을 때
마찬가지로 SPA가 아닌 정적 웹사이트는 잘 불러왔지만, SPA는 하위 링크를 불러오지 못했다.
5. 네 번째 시도: JS 라이브러리인 puppeteer 사용
puppeteer의 특징
- SPA 화면의 렌더링이 가능하다
- 렌더링후 키보드, 마우스 입력 제어할 수 있다.
- 웹페이지의 자동 테스트 도구를 만들 수 있다.
- 각각의 웹페이지 crawling 이 가능하다.
- CSR, SSR 모두 크롤링 가능하다.
selenium을 사용하지 않고 puppeteer를 사용한 것은 첫번째 특징인, SSR 페이지의 pre-rendering이 가능하다는 점이었다.
사용 코드
<code />
const puppeteer = require('puppeteer');
const fs = require('fs');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
await page.goto('https://www.banksalad.com/');
// Wait for SPA content to load (you may need to adjust this)
await page.waitForSelector('a');
const links = await page.evaluate(() => {
const linkElements = document.querySelectorAll('a');
return Array.from(linkElements).map((element) => element.href);
});
// Save links to a file
fs.writeFileSync('links2.txt', links.join('\n'));
console.log('Links have been saved to links.txt');
await browser.close();
})();
puppeteer로 하위 링크를 뽑아내기 위해서는 스크래핑하기 위한 선택자를 지정해주어야 했다.
가장 일반적으로 사용하는 a태그를 선택자로 주고 시도해보았다.
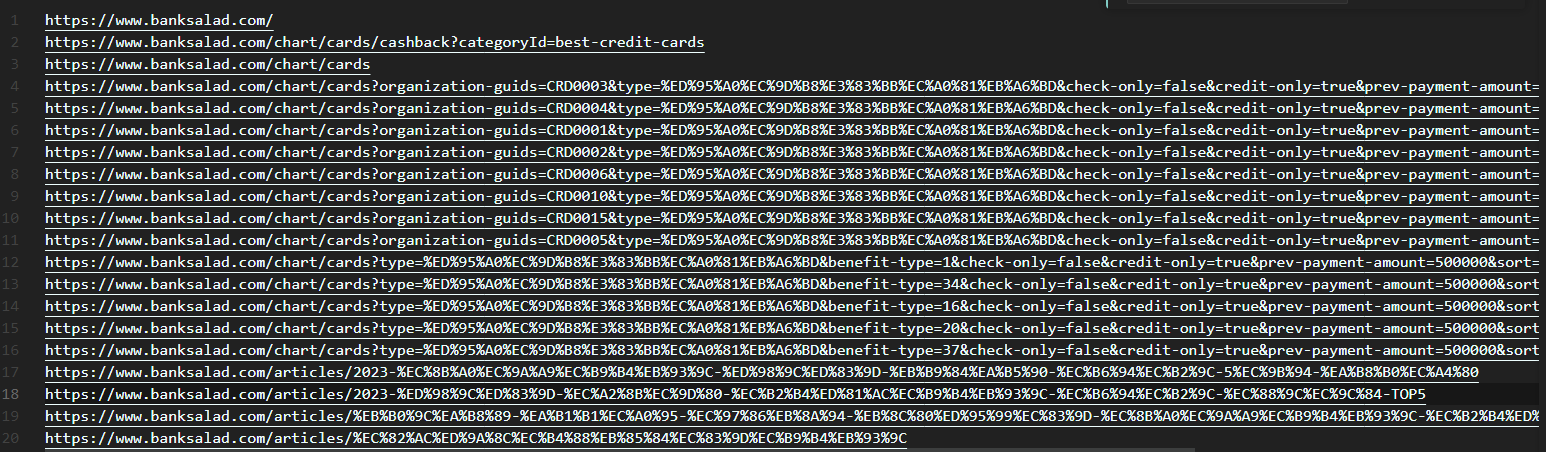
꽤나 유의미한 결과가 나왔다.
SPA 사이트에서 약 386개의 하위 도메인이 추출되었다.
그러나 다음과 같은 단점들이 존재했다.
- 선택자가 a태그가 아닌 button, cursor , label , 등등.. 이라면 그에 따른 처리가 필요하나 이 부분은 상식적으로 정의가 불가능하다.
6. 🚨 문제상황 🚨
puppeteer의 단점이 선택자로 지정해서 크롤링하는 것이므로, 해당 태그를 사용하는 이외의 방식으로 링크를 제작한 경우 크롤링이 안됨.
문제점
링크를 선언하는 방식이 다양하여, 각각 전처리를 해줄 필요가 있으나 경우가 너무 많다.
ex)
Tag
- list , a , button 등등
value
- href = "/example" , moveHref('./example')
- 이외에도 location, assign 등등..
6.0.1. 시도 1: 정규식 이용
html 코드를 프리렌더링 한 뒤, ‘./’ 으로 시작하는 문자열등을 파싱 후 url 만들기
➡️ 잘 작동되는 듯 하나 , 만약 index로 페이지를 이동하거나, 자체 메서드를 사용하는 경우에는 잘 작동하지 않는다. 예외 상황도 많이 발생할 것으로 예상
6.0.2. 시도 2: onclick 이벤트 모두 발생
프리 렌더링된 코드에서 링크만 따로 직접 크롤링하는 방법.
onclick 이벤트를 모두 발생 시키고 url이 변경되는 경우에만 변경된 url을 저장하는 등의 방법 사용.
단순한 해결법으로는 onclick 이벤트가 발생할 때마다 모든 페이지를 다시 파싱하고, 저장해둔 index를 다시사용하는 방법
해당 방식의 문제점
➡️onclick으로 페이지를 이동할 경우 다시 원래 페이지로 돌아온 후 기존 index를 다시 찾지 못하는 문제 발생, 따라서 전체 페이지를 다시 불러와야함.
➡️실행시간이 기하급수적으로 증가
➡️링크를 onclick으로 처리하지 않는 사이트 또한 존재하므로 결국 전부 처리하진 못함.
결론 : 기존 a태그를 기준으로 파싱하는 방식이 가장 '일반적'이고, 가장 많은 웹사이트에 통용될 것이라 판단.
위험한 문제점
- 만약 유튜브 혹은 플레이스토어 같은 외부 링크로 이어지는 경우, 깊숙하게 하위 링크를 찾는 과정에서 유튜브는 무한하게 링크를 타고 들어갈 수 있으므로 프로그램이 고장날 우려 존재. ➡️※9번 추가기능 항목 2에서 해결
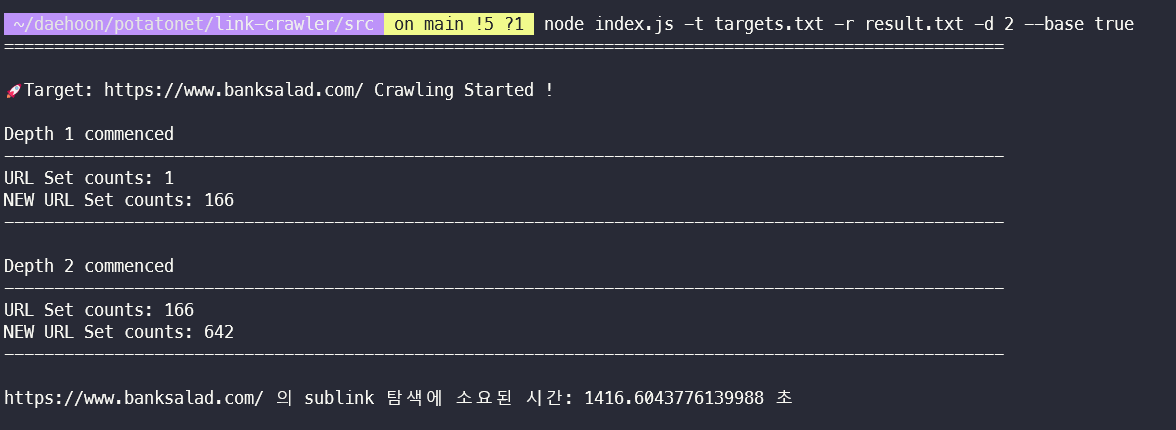
7. 테스트 결과
테스트 웹 : banksalad.com
Depth 1로 테스트
Depth 2로 테스트
170개의 하위링크 + 하위링크에서 추가로 파생된 1040개의 링크를 확인할 수 있었다.
Depth2의 총 소요시간은 1392초로, 약 20분의 시간이 소요되었다.
사이트의 크기와 추가로 걸러내야 할 외부링크등을 고려하면, 실 사용에 큰 문제는 없을 것이라 판단된다.
Depth를 3으로 지정하고 크롤링 - 현재 진행중
8. 기타 변경 사항 / 트러블 슈팅
8.1. 베이스 url만 포함하도록 처리

baseurl이 포함되지 않으면 해당 링크를 처리하지 않는 옵션 추가.
baseurl을 포함해야하는 옵션 —base true를 추가해 진행하자 약 400개의 url이 추가로 걸러진 모습이다.
해당 옵션은 사용자가 on/off 를 선택할 수 있다. (default : false)
8.2. 재귀 시 오류 처리하기
베이스 url만 포함하도록 하여 외부 사이트로 접속되는 문제는 해결
한번 접속한 url / 메인 페이지를 재 접속하는 문제 해결
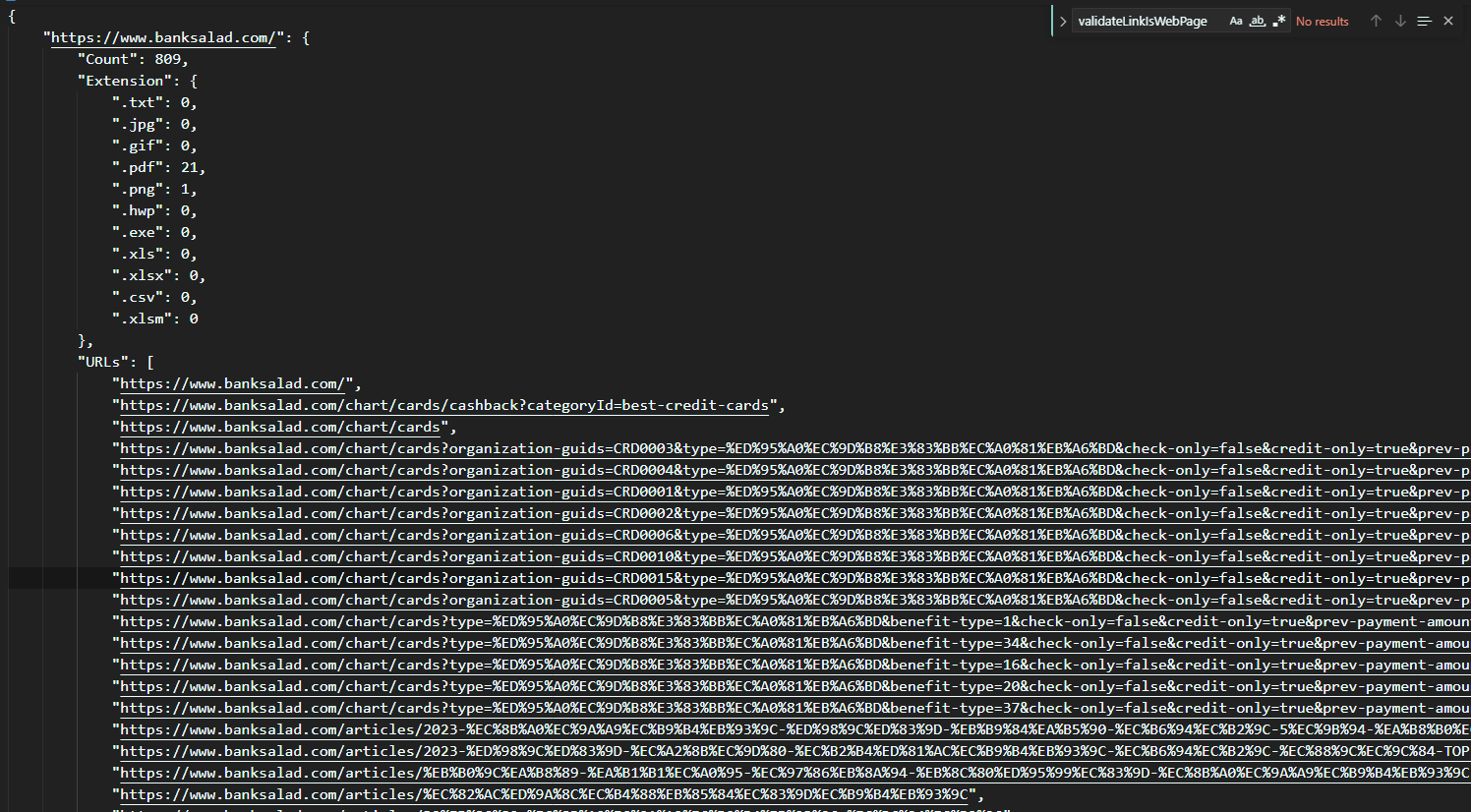
8.3. 테스트 결과
테스트 웹 : banksalad.com
Depth 1로 테스트
Depth 2로 테스트
170개의 하위링크 + 하위링크에서 추가로 파생된 1040개의 링크를 확인할 수 있었다.
Depth2의 총 소요시간은 1392초로, 약 20분의 시간이 소요되었다.
사이트의 크기와 추가로 걸러내야 할 외부링크등을 고려하면, 실 사용에 큰 문제는 없을 것이라 판단된다.
Depth를 3으로 지정하고 크롤링 : 5183초, 약 86분 소요

8.4. Page Crashed 문제 해결
What is "Page crashed!" error? · Issue #1321 · puppeteer/puppeteer
Steps to reproduce N/A (Not able to reproduce consistently.) Tell us about your environment: Puppeteer version: master Platform / OS version: Docker image based on Node:8.5 https://gist.github.com/...
github.com
위 이슈 참고 결과 linux 환경 혹은 도커/k8s 환경에서는 ****메모리**** 문제일 확률이 높다.
page launch 시 '--disable-dev-shm-usage' 옵션을 통해 공유 메모리 사용을 막고, 가상 메모리를 더 할당해주는 방식으로 해결 가능
결과 : Depth3까지 정상 탐색 성공 확인
8.5. Error: net::ERR_NETWORK_CHANGED at ~ 에러 해결
page.goto() method generates Error:≠t::Eℝ error · Issue #1477 · puppeteer/puppeteer
Steps to reproduce My environment: (also, I got the same error on https://try-puppeteer.appspot.com/) Puppeteer version: v0.13.0 Platform / OS version: MacOS Sierra 10.12.6 URLs (if applicable): ht...
github.com
Error: net::ERR_NETWORK_CHANGED at ~ 버그 발생
puppteer page goto문 전에 다음 옵션 추가
<code />
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3419.0 Safari/537.36');
User-agent 설정을 통해 헤더를 설정하여 해당 웹페이지에 접근 시 크롬 브라우저에서 접근한 것으로 인식하도록 함.
항상 이 에러가 발생하지 않는 것으로 유추해 본 결과, HeadlessChrome을 크롬대신 사용하였고 웹 서버가 이를 브라우저에서 오는 요청으로 인식하지 못할 수 있다고 생각
8.6. ERR_SSL_PROTOCOL_ERROR at ~ 에러 해결
Certificates error using puppeteer · Issue #2377 · puppeteer/puppeteer
Hello, I encountered a weird ssl problem using puppeeter 1.2.0 or 1.3.0 (inside a container). Looking at this example (works on https://try-puppeteer.appspot.com/) const browser = await puppeteer.l...
github.com
SSL 인증서 관련 에러가 발생했다.
이는 HTTPS 와 HTTP관련 에러를 모두 무시하는 옵션을 주어서 해결했다.
page launch 시 ignoreHTTPSErrors: true , ignoreHTTPErrors 옵션 추가.
8.7. 속도 개선 방안
SPA여부를 확인하고 SPA가 아니라면 다른 크롤러를 사용한다면 어떨까?
8.8. 크롤러 속도 비교 Selenium vs Puppeteer vs HTTP-Client
Selenium VS Puppeteer VS HTTP Client | Ahea Team Study Blog
Publish Date: 2019-05-01 Read Count:
devahea.github.io
Puppeteer 와 HTTP-Client의 속도는 약 6배 차이다.
그렇다면 SPA가 아니라면 HTTP-Client로 크롤링을 하면 어떨까?
8.9. SPA 판단 가능 여부
불가능하다 ?
How to know if a website is a single page application?
I have extremely little experience with web tech, only know basic HTML and CSS. I have an assignment where I'm supposed to evaluate a website and identify web techs that can help improve the site. ...
stackoverflow.com
-> 생각해보니 의미가 없다,, 메인 페이지는 정적 페이지 이지만,
하위링크를 타고 들어간 페이지가 동적 페이지라면? ➡️ 다시 퍼페티어를 쓴다 ➡️ 오버헤드가 심할듯 함ex)네이버 지도
9. ++추가 기능
사용자가 지정한 확장자의 개수를 탐지하여 저장하는 기능
Base URL이 아닌 경우, 해당 Sublink는 저장은 하되 깊이 탐색은 실시하지 않음
10. 사용 예시
11. 이미지화하여 dockerhub에 업로드
이제 해당 프로그램을 도커로 이미지화 해보자.
만약 도커가 처음이라면, 다음 포스팅을 보고 초기 세팅을 할 것!
[CI/CD] - 도커와 젠킨스를 사용한 CI/CD -1 (도커의 설치부터 자동배포까지)
오늘은 window wsl2 ubuntu18.04환경에서 도커를 설치하고, 젠킨스를 이용해 자동 배포 파이프라인을 구축해 볼 예정이다. 자동 배포의 필요성 기존 팀 프로젝트의 work flow는 다음과 같았다. 각자 기능
kangmanjoo.tistory.com
11.1. Dockerfile 파일 생성
먼저 Dockerfile을 만들어주자.
puppeteer를 서버에서 실행하려면, 가상 브라우저를 사용하므로 chromium과 기타 패키지들을 설치해주어야한다.
파일 내용은 다음과 같이 적어준다.
자세한 사항은 주석을 확인하자.
<java />
FROM node:16-alpine # Node.js 16과 alpine Linux를 기반으로 하는 이미지 사용
RUN apk add --no-cache chromium nss freetype harfbuzz ca-certificates ttf-freefont udev xvfb x11vnc fluxbox dbus # puppeteer 실행을 위해 필요한 패키지들을 설치
RUN apk add --no-cache --virtual .build-deps curl \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/main" >> /etc/apk/repositories \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/community" >> /etc/apk/repositories \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/testing" >> /etc/apk/repositories \
&& apk add --no-cache curl wget \
&& apk del .build-deps # puppeteer 다운로드를 위해 필요한 라이브러리들을 설치하고 마지막에는 빌드를 위해 추가적으로 설치한 패키지들을 삭제
ENV PUPPETEER_EXECUTABLE_PATH=/usr/bin/chromium-browser # puppeteer가 chromium-browser를 실행할 수 있도록 설정
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true # 이미 chromium을 설치했기 때문에 puppeteer가 chromium을 다시 다운로드하지 않도록 설정
ENV DISPLAY=:99 # Xvfb에서 사용할 디스플레이 설정
WORKDIR /var/app # 작업 디렉토리를 /var/app으로 설정
# 캐시를 이용해 npm 패키지 설치를 한번만 실행하도록 합니다.
COPY package.json package-lock.json ./
RUN npm ci --only=production # production 환경에서 필요한 모듈들만 설치
RUN npm install puppeteer # puppeteer 설치
COPY . .
RUN npm run build # 앱 빌드
ENV NODE_OPTIONS="--max-old-space-size=2048" # 메모리 사용량 설정
EXPOSE 3030 # 컨테이너의 포트를 3030으로 열어줌
CMD Xvfb :99 -screen 0 1024x768x16 -ac & node src/index.js -t targets.txt -r result.txt -d 1 # Xvfb를 실행하고, node 앱 실행
CMD에 작성된 Xvfb는 가상화된 X Window 시스템을 생성해주는 X11 서버라고 한다. 이를 통해 실제로 화면이 없는 서버 컴퓨터에서도 그래픽 사용자 인터페이스(GUI) 기반의 어플리케이션을 실행시킬 수 있다고.. Puppeteer는 Chromium을 브라우저 엔진으로 사용하기 때문에, 해당 브라우저의 GUI 기능을 사용해야 하고 따라서, xvfb를 통해 GUI를 구현하는 환경을 만들어주어 Puppeteer가 정상적으로 동작하도록 한단다.
참고 문헌:
[Docker] docker로 puppeteer 크롤링 프로젝트 배포시 오류 해결하기
주말에 끝내고 말겠다는 집념으로 무사 배포에 성공했다. 결론적으로 http라서 배포에 헤맸던 것은 아니었다. 도커파일과 크롤링해오는 service.ts파일을 수정해주었더니 http에서도 크롤링 데이터
velog.io
dockerignore 파일도 만들어주자.
세부 사항은 다음과 같이 적어준다.
<java />node_modules npm-debug.log
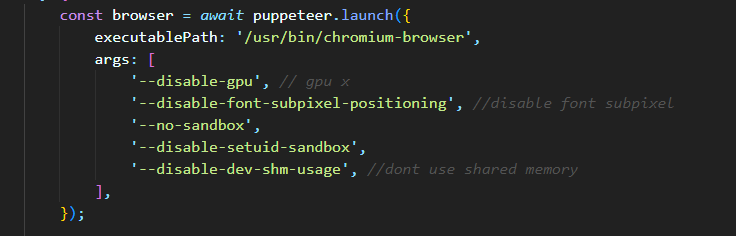
++ 추가로 puppeteer.launch도 다음 코드를 추가해주어야한다.
<java />
executablePath: '/usr/bin/chromium-browser',
11.2. 도커파일 빌드하기
다음 명령어로 빌드를 해준다. 뒤에 :{tag}를 붙여 태그도 지정해 줄 수 있다.
<java />docker build . -t {dockerhub 이름}/{프로그램명}
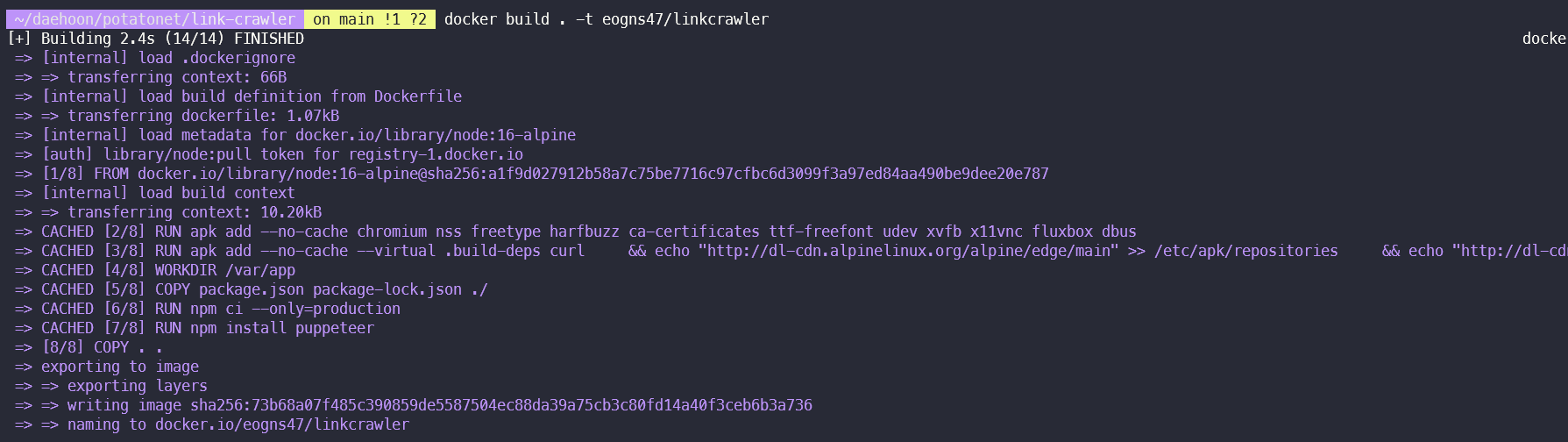
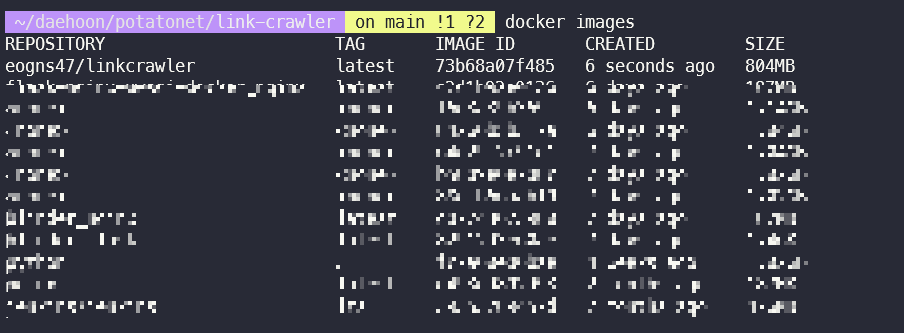
빌드가 성공적으로 됐는지 docker images로 확인해준다.
11.3. 도커이미지 컨테이너화
우선 볼륨을 먼저 만들어주어야하는데, 다음 포스팅에 자세한 설명이 있다.
[CI/CD] - 도커와 젠킨스를 사용한 CI/CD -2 (도커의 설치부터 자동배포까지)
2023.10.21 - [분류 전체보기] - [CI/CD] - 도커와 젠킨스를 사용한 CI/CD -1 (도커의 설치부터 자동배포까지) 도커의 설치와 기본 세팅은 위 포스팅에 정리되어있다. 젠킨스 이미지 다운 docker pull jenkins/je
kangmanjoo.tistory.com
다음 명령어로 이미지를 컨테이너화 시켜준다.
<java />
docker run -d -v myV:/var/app/results --name newcrawler eogns47/linkcrawler
옵션은 다음과 같다.
- -d :
- 보통 데몬 모드라고 부르며, 컨테이너가 백그라운드로 실행된다.
- -v :
- 데이터 볼륨 설정이다.
- 호스트와 컨테이너의 디렉토리를 연결하여, 파일을 컨테이너에 저장하지 않고 호스트에 바로 저장한다.(마운트)
- 데이터 볼륨을 설정해줌에 따라 결과물을 로컬파일에서 확인 가능하다.
- --name:
- 해당 컨테이너의 별명이다.
11.4. 컨테이너 터미널 접속 후 프로그램 실행
다음 명령어로 컨테이너의 터미널에 연결한다.
<java />docker exec -it newcrawler /bin/sh
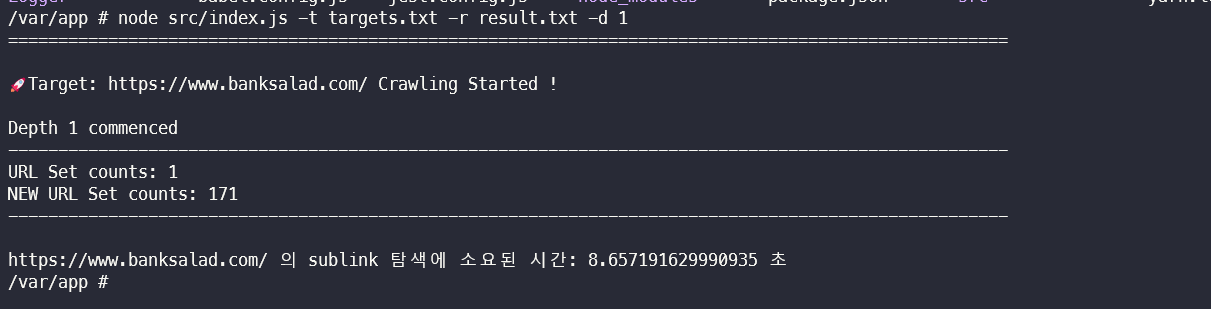
이후 원하는 옵션을 주어서 프로그램 실행.
<java />
node src/index.js -t targets.txt -r result.txt -d 1
실행 예시
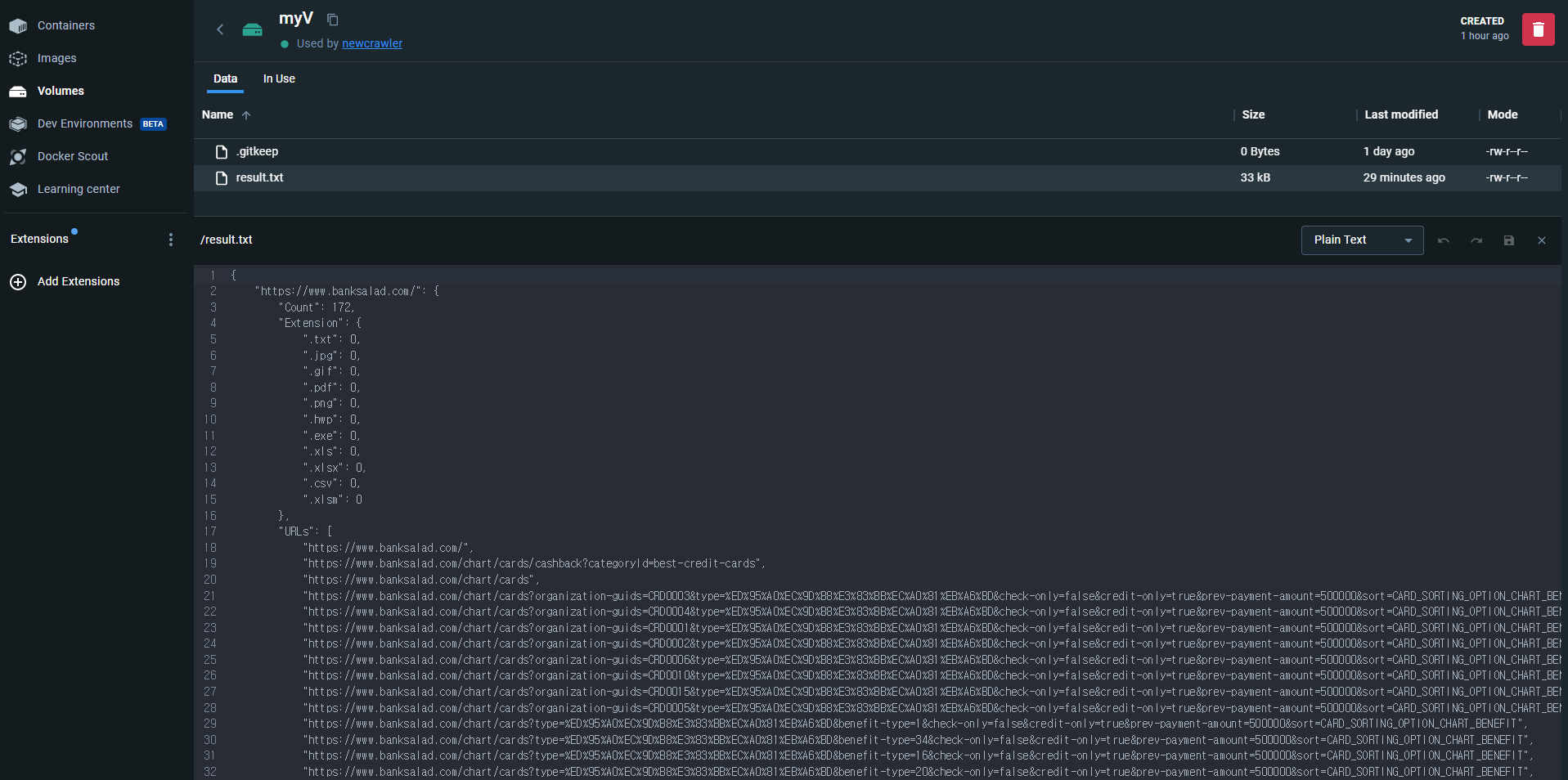
11.5. 마운트에서 데이터 확인
12. 도커 허브에 업로드
기존 만들어둔 도커허브 아이디로 쉘에서 로그인한다.
<java />docker login
기존에 만들어둔 이미지 이름으로 push를 한다.
이미지 이름에 도커허브 아이디를 넣지 않았다면 push가 불가능하다.
<java />docker push {도커허브 이름}/{프로그램명}
웹에서도 확인이 가능한 모습이다.
이제 어디서든 해당 이미지를 다운받아 크롤러를 실행 가능하다.
12.1. 트러블 슈팅
배포 서버와 개발 서버의 아키텍쳐가 달라 도커 이미지가 호환되지 않았다.
해당 문제는 다음 포스팅의 방법으로 해결하였다.
[Docker] - 배포 서버와 개발 환경의 Platform이 다를때 : The requested image's platform (linux/amd64) does not match
문제 상황 개발환경에서 DockerHub에 Docker 이미지를 푸시하고, 배포서버에서 pull해서 사용하려고 하자 실행시 WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8)
kangmanjoo.tistory.com
13. V2 업데이트 (24.01.17)
크롤링은 정상적으로 진행되나, 배포서버에서 크롤링의 진행률을 확인할 방법이 없었다.
로그로 일일이 진행도를 찍어가면서 보는 것도 번거로울 뿐더러, 크롤러의 코드를 수정하고 싶지 않았다.
기존에 results.txt만 제공하던 방식에서, 다음 내용들을 추가로 로그로 보여주고 싶었다.
- 전체 크롤링 로그
- 총 url 개수에 대한 현재 진행률
- 크롤링하지 못한 사이트 목록
13.1. 해결책 - index.js를 실행하는 파이썬 프로그램을 만들고, 파이썬의 tqdm 모듈을 활용
먼저 기존 프로그램 루트에, exec.py라는 파이썬 프로그램을 하나 만들 것이다.
이 프로그램의 역할은 다음과 같다.
- 크롤링 해야할 전체 URL이 담긴 targets.txt를 읽는다.
- 해당 URL을 배열에 저장 후, 반복문을 돌며 하나의 URL이 담긴 tmp.txt 파일을 생성한다.
- index.js에 타겟 인자로 tmp.txt를 전달한다.
- 이외의 index.js의 인자는 모두 exec.py의 인자로 대신 받아서 전달한다.
tqdm 모듈을 사용해 진행률을 보여주는 예시
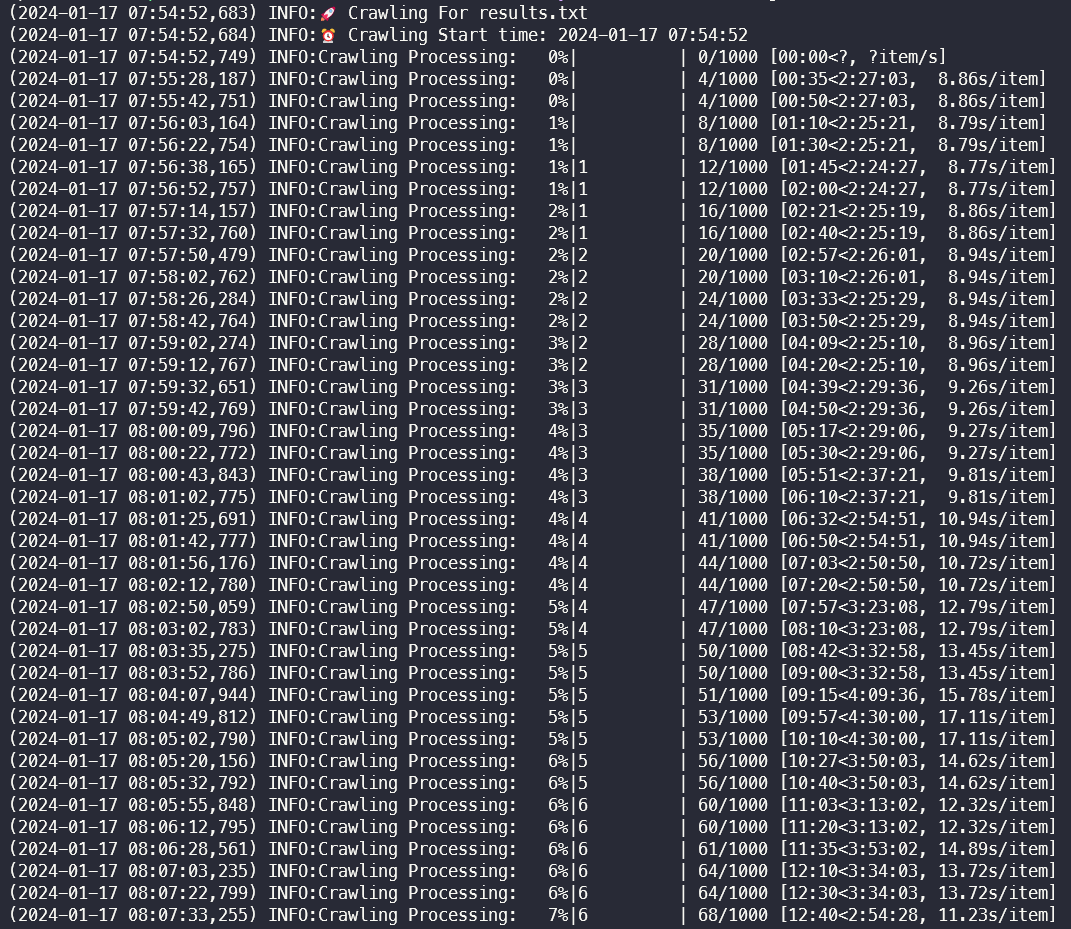
전체 크롤링 로그 예시
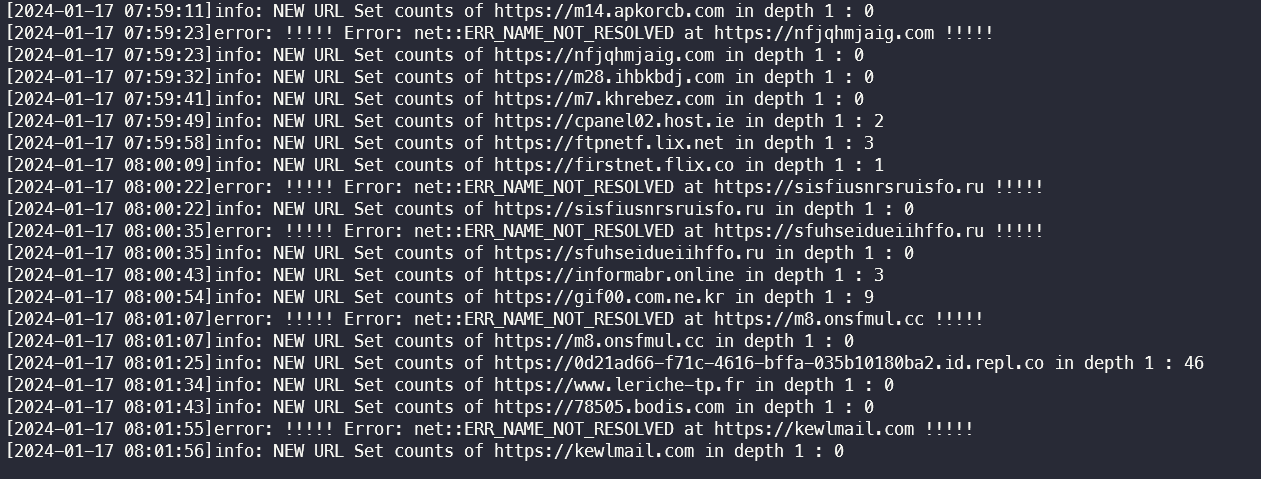
에러 리스트 예시
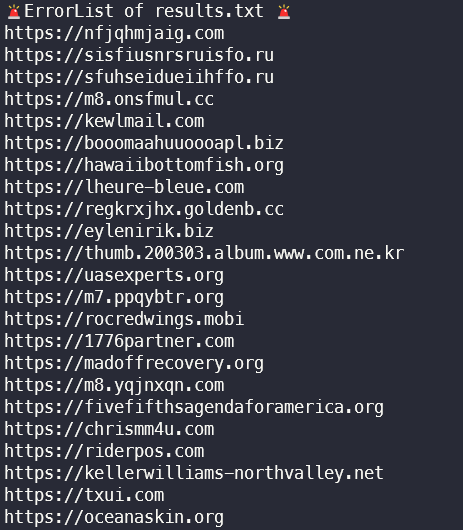
에러 리스트의 경우, errorList.txt파일에 outputfile 이름을 기준으로 나누어 append하도록 하였다.
13.2. Dockerfile 수정
파이썬 코드가 새로 추가됨에 따라 Dockerfile도 수정이 있었다.
<go />
FROM node:16-alpine
RUN apk add --no-cache chromium nss freetype harfbuzz ca-certificates ttf-freefont udev xvfb x11vnc fluxbox dbus
RUN apk add --no-cache --virtual .build-deps curl \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/main" >> /etc/apk/repositories \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/community" >> /etc/apk/repositories \
&& echo "http://dl-cdn.alpinelinux.org/alpine/edge/testing" >> /etc/apk/repositories \
&& apk add --no-cache curl wget \
&& apk del .build-deps
# Copy Python files and install additional pip packages
# Copy files under ExecBot directory
ENV PUPPETEER_EXECUTABLE_PATH=/usr/bin/chromium-browser
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true
ENV DISPLAY=:99
WORKDIR /var/app
# 캐시를 이용해 npm 패키지 설치를 한번만 실행하도록 합니다.
COPY package.json package-lock.json ./
RUN npm ci --only=production
RUN npm install puppeteer
COPY . .
ENV NODE_OPTIONS="--max-old-space-size=2048"
# Install Python and pip packages
RUN apk add --no-cache python3 py3-pip gcc musl-dev python3-dev
RUN python3 -m venv /path/to/venv
ENV PATH="/path/to/venv/bin:$PATH"
RUN . /path/to/venv/bin/activate && pip install -r /var/app/ExecBot/requirements.txt
EXPOSE 8090
CMD Xvfb :99 -screen 0 1024x768x16 -ac
# Path: .dockerignore
Alpine Linux는 시스템 전역의 Python 환경이 시스템 패키지 매니저를 통해서만 관리되어야 한다는 규칙을 갖고 있다.
따라서 다음과 같은 순서를 따랐다.
가상 환경 사용:
가장 간단한 해결책으로 Python 패키지를 가상 환경 내에 설치하였다. Dockerfile에서 다음과 같이 가상 환경을 만들어 패키지를 설치하도록 변경하였다.
<code />
RUN apk add --no-cache python3 py3-pip gcc musl-dev python3-dev
RUN python3 -m venv /path/to/venv
RUN . /path/to/venv/bin/activate && pip install -r /var/app/ExecBot/requirements.txt
위처럼 코드를 쓸 경우 빌드는 잘 됐지만,
크롤링을 하려 도커 쉘에 접속해 실행하면 가상환경이 켜져있지 않아 매번 가상환경을 켜주어야 했다.
따라서 마지막 줄을 다음과 같이 수정하였다.
<code />
ENV PATH="/path/to/venv/bin:$PATH"
RUN pip install -r /var/app/ExecBot/requirements.txt
환경 변수 **PATH**를 설정하여 가상 환경의 bin 디렉토리를 환경 변수 **PATH**에 추가하였다. 이렇게 하여 가상 환경이 활성화된 것과 동등한 효과를 누릴 수 있다.
13.2.1. 로그폴더 마운트
그리고 원하는 로그들만을 선택하여 보기 위해서, 도커 볼륨에 마운트할때에는 다음과 같이 여러번 나누어서 마운트 해주었다.
<go />
docker run -d -v myV:/var/app/results -v myV:/var/app/logs --name newcrawler eogns47/linkcrawler:new
이상으로 도커 이미지를 다운 받아서, python 명령어를 하나만 주면 모든 크롤링 동작과 로깅이 자동화되어 편리함을 누릴 수 있게되었다.
14. 성능 개선 (24.01.17)
puppeteer가 좀비 프로세스를 종료하지 않는 문제로 인해 메모리 손실이 심하게 일어났고, 이를 방지하고자 코드를 수정하였다.
자세한 내용은 다음 포스팅에 정리되어있다.
[Puppeteer / Trouble Shooting] puppeteer가 좀비 프로세스를 종료하지 않는 문제
puppeteer로 만든 프로그램을 돌리는 중, chromium 브라우저가 종료되지 않는 문제가 발생했다. 다음 명령어로 chromium 창이 몇개 떠 있는지 확인해보자. pgrep chromium | wc -l 949개?! 엄청난 메모리 손실을
kangmanjoo.tistory.com
15. 사용 기술
16. github
GitHub - eogns47/Sublink-Crawler
Contribute to eogns47/Sublink-Crawler development by creating an account on GitHub.
github.com
17. Dockerhub
Docker
hub.docker.com
