엘라스틱 서치(ES)의 모든 기능은 REST API 형태입니다.
몇가지 예시는 다음과 같습니다.
테스트는 키바나 → Management → Dev Tools 에서 실행했습니다.
POST /user/_doc/3
{
"name": "kim",
"age": 10
}➡️ es_index라는 인덱스를 만들고 1번 도큐먼트를 생성한다.
GET user➡️ user를 조회한다.
GET user/_doc/3➡️ user 내부의 3번 도큐먼트만 조회한다.
DELETE user➡️ user를 삭제한다.
GET _cat/indices?v➡️내부 인덱스 목록을 확인한다. (앞서 DELETE를 했다면 user가 삭제된 것을 확인할 수 있다.)
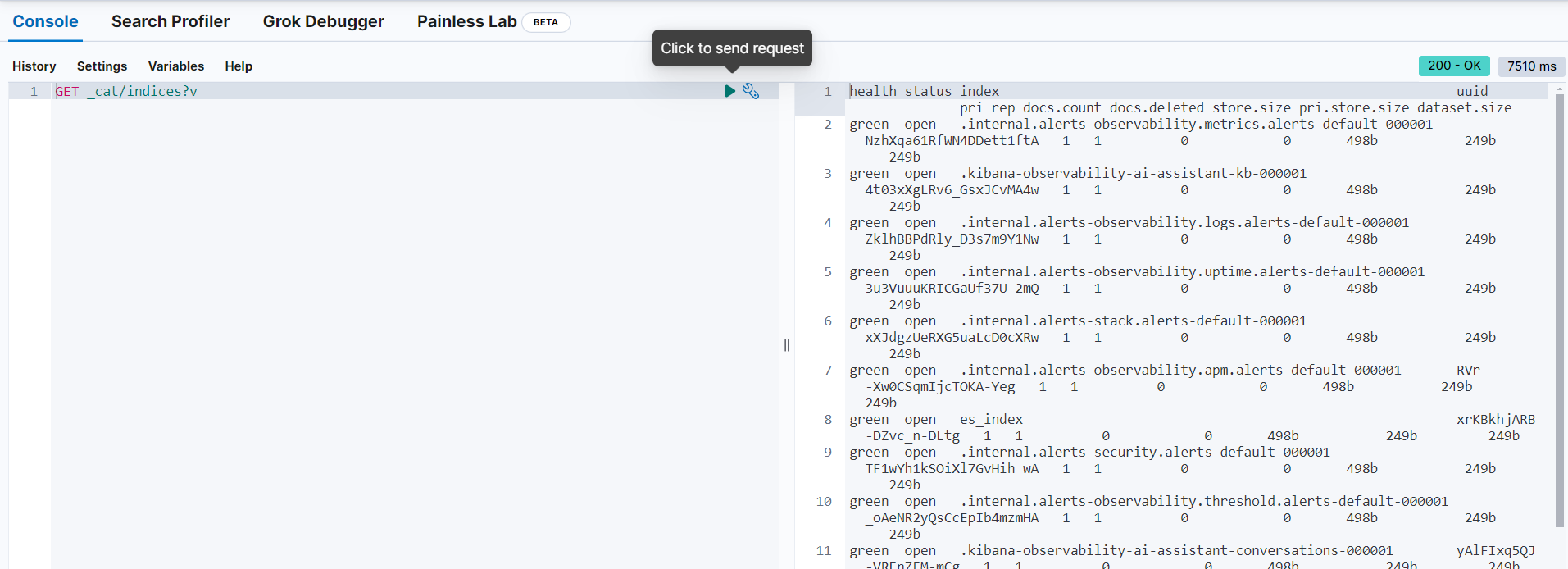
인덱스, 도큐먼트.. 기존 RDB에서도 쓰는 용어이지만, 뭔가 개념이 다르다는 것이 느껴집니다.
하나씩 정리해보겠습니다.
인덱스 (Index)
인덱스는 RDBMS에서의 데이터베이스에 해당합니다. 사용자 인덱스, 상품 인덱스 등 성격에 맞게 자유롭게 생성할 수 있습니다. 하나의 인덱스는 하나 이상의 타입(type)을 포함합니다. 타입은 RDBMS에서의 테이블에 해당하며 도큐먼트들의 논리적 그룹을 정의합니다.
그러나 7.0 버전부터는 인덱스당 타입이 하나만 제공되어서, 사실상 인덱스 == 타입이라고 생각할 수 있습니다. 따라서 한 데이터베이스당 한 테이블만 존재한다고 볼 수 있겠습니다.
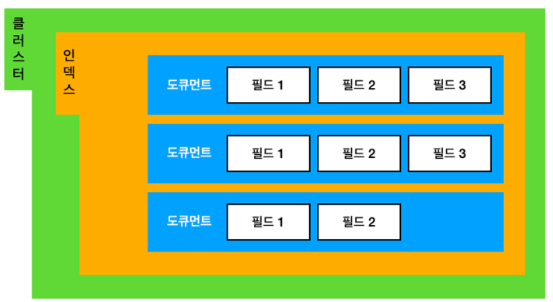
위 그림과 같이 한 클러스터 내에 여러 인덱스가 있고, 인덱스 내부에는 JSON 형태의 여러 도큐먼트가 존재하는 형태입니다. 그리고 각 도큐먼트는 복수의 필드를 갖습니다.
이 도큐먼트(JSON 데이터)들을 성격에 맞게 저장하는 구분자가 인덱스입니다.
샤드 (Shard)
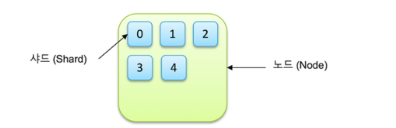
엘라스틱 서치는 인덱스에 데이터를 저장하고, 인덱스는 샤드라는 단위로 분리되어 각 노드에 분산 저장됩니다.
샤드는 일반적으로 20~40GB의 데이터가 저장되는 것이 좋습니다.
이를 위해 인덱스를 정의할 때 setting 필드에 정의를 해주거나, 다음 코드와 같이 템플릿을 만들어 놓으면 인덱스가 생성 될 때 자동으로 샤드 개수가 정해집니다.
setting 필드에 정의를 해주는 경우
$ curl -XPUT "http://localhost:9200/user" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'템플릿을 만드는 경우
PUT _template/2_shard
{
"order" : 0,
"index_patterns" : [
"my-*",
"test-*"
],
"settings" : {
"index" : {
"number_of_shards" : "3",
"number_of_replicas" : "1"
}
},
"mappings" : { },
"aliases" : { }
}
레플리카(Replica)

ES는 분산 저장소이므로 여러개의 노드(서버)를 사용하게 됩니다.
레플리카는 ES의 백업 솔루션이라고 볼 수 있습니다.
레플리카를 2개로 설정하면, 원본 샤드 1개당 대응하는 레플리카 샤드를 1개씩 생성합니다.
레플리카를 3개로 설정하면 원본 샤드 1개당 대응하는 레플리카 샤드를 2개씩 생성합니다.
따라서 처음 생성된 샤드를 프라이머리 샤드, 복제본을 레플리카라고 합니다.

만약 위 그림의 클러스터에서 노드 3번이 유실되었다고 가정합니다. 이 때는 다른 노드에 여전히 0번과 4번 샤드가 살아있으므로 데이터는 유실되지 않습니다.
이후 클러스터는 3번 노드의 복구를 기다리고, 타임아웃이 된다면 복제본이 사라진 0번샤드와 4번샤드의 재복제를 실행합니다.
이렇게 클러스터는 프라이머리 샤드와 레플리카의 개수를 유지합니다.
🚨만약 노드가 1개라면 레플리카는 생성되지 않습니다.🚨
따라서 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것을 권장합니다.
노드(Node)
ES는 하나 이상의 노드들로 이루어집니다. 엘라스틱 서치 클러스터를 운영하기 위해서는 다수의 물리 서버에 ES를 설치하고 실행하는데, 실행된 ES 인스턴스 각각을 노드라고 합니다.
분산 처리를 위해서 다양한 형태의 노드들을 조합해서 클러스터를 구성해야 하는데, ES는 4가지 유형의 노드를 제공합니다.
- 마스터노드
- 데이터 노드
- 인제스트 노드
- 코디네이팅 노드
마스터 노드(Master Node)
노드 중 인덱스의 메타 데이터, 샤드의 위치와 클러스터 상태 정보 등을 관리하는 노드를 마스터 노드라고 합니다. 클러스터마다 하나의 마스터 노드가 존재하고, 마스터 노드가 없다면 클러스터는 작동을 정지합니다.
엘라스틱 서치에서는 디폴트 값으로 모든 노드가 마스터 후보 노드입니다. 만약 마스터 노드가 다운되면 마스터 후보 노드 중 하나가 마스터 노드로 선출되어 마스터 노드의 역할을 대신 수행합니다.
마스터 후보 노드들은 마스터 노드의 정보를 공유하고 있기 때무에 즉시 마스터 역할의 수행이 가능합니다.
Split Brain 현상을 방지하기 위해서 마스터 후보 노드는 항상 3개 이상의 홀수 개로 놓는 것이 권장됩니다.
Split Brain현상이란?
마스터 후보 노드가 단절되었을 때, 각각이 마스터 노드가 되어 서로 다른 클러스터들로 구성되어 동작하는 것. 이 상태에서 클러스터의 데이터에 변화가 생기면, 추후 다시 병합할 때 데이터 정합성에 문제가 생기고 데이터 무결성이 유지될 수 없다.
7.0 버전 이전에서는 Split Brain 현상을 방지하기 위해 elasticsearch.yml에서discovery.zen.minimum_master_nodes 옵션을 (전체 마스터 후보 노드 / 2) +1로 설정해주어야합니다.
7.0 버전 이후에는 마스터 후보 노드가 추가될 때마다 클러스터가 스스로 값을 변경하므로 신경써주지 않아도 됩니다.
데이터 노드(Data Node)
도큐먼트가 실제로 저장되는 노드로, 즉 데이터가 실제로 분산 저장되는 물리적 공간인 샤드가 배치되는 노드입니다.
색인할 문서가 적으면 마스터 노드와 함께 구성해도 괜찮지만, 그렇지 않다면 분리해서 구성합니다.
인제스트 노드(Ingest Node)
색인에 앞서 데이터를 전처리하기 위한 노드입니다.
데이터의 포맷을 변경하기 위해 스크립트로 전처리 파이프라인을 구성하고 실행할 수 있습니다.
코디네이팅 노드(Coordinating Node)
다른 노드의 역할을 하지 않고 오로지 들어온 요청을 분산시켜주는 노드입니다.
검색이나 집계 시 분산 처리만을 목적으로 합니다.
도큐먼트 (document)
도큐먼트는 JSON 형식으로 표현되는 단일 데이터 단위입니다. 도큐먼트들이 인덱스에 저장되어 검색과 분석이 가능해집니다. 도큐먼트는 엘라스틱 서치에서 다루는 데이터의 최소 단위이며, 각 도큐먼트는 유일한 ID로 구분됩니다. RDB의 row와 매칭되는 개념입니다.
그러나 RDB의 row와는 달리 구조가 정해져있지않아 어떤 문서라도 데이터를 자유롭게 넣을 수 있습니다.
기본적으로 ES의 도큐먼트는 Key-Value로 이루어지고, Key는 컬럼명, Value는 컬럼값이라고 생각할 수 있습니다.
만약 POST로 도큐먼트를 넣을 때 ID 값을 입력하지 않고 넣으면, Primary key인 _id가 자동으로 generate됩니다.
매핑 (Mapping)
매핑은 인덱스 내의 타입에 대한 스키마(schema)를 정의하는 것을 의미합니다.
스키마는 해당 타입에 저장되는 도큐먼트들의 구조와 데이터 타입을 정의합니다.
쉽게 생각해서 RDBMS에서 나이는 int, 이름은 string .. 이렇게 타입을 지정해주는 것을 매핑이라고 볼 수 있습니다.
매핑은 크게 두 종류가 있습니다. 바로 다이나믹 매핑과, 명시적 매핑입니다.
다이나믹 매핑은 인덱스에 도큐먼트를 추가할 때 ES가 필드들의 데이터 타입을 자동으로 추측하고 동적으로 매핑하는 것입니다.
명시적 매핑은 개발자가 직접 매핑을 정의하는 것으로, 인덱스를 생성할 때 사용합니다.
다이나믹 매핑은 무조건 데이터 타입 중 가장 큰 값을 할당합니다. ( 예를 들어 정수가 들어오면 long 할당)
따라서 메모리 낭비를 막기 위해서는 알고 있는 데이터 정보에 한해서는 명시적 매핑을 해주는 것이 좋습니다. 만약 인덱스에 명시적 매핑이 되지 않은 필드를 포함한 도큐먼트가 들어오면, ES는 해당 필드만 다이나믹 매핑을 진행해줍니다.
멀티 필드 (Multi Field)
ES의 도큐먼트에는 하나의 필드값만을 가지고 있지만, 이 필드의 값을 여러 개의 색인으로 저장할 수 있는 것을 멀티 필드라고 합니다.
멀티 필드가 필요한 이유는?
보통은 text 타입 아래에 keyword 타입을 정의하기 위해 사용한다. 하지만 이 외에도 하나의 텍스트 필드에 여러 애널라이저를 적용하기 위해서도 사용됩니다.
이는 다국어로 이루어진 도큐먼트를 분석할 때 매우 유용합니다.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"nori_analyzer": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
},
"nori": {
"type": "text",
"analyzer": "nori_analyzer"
}
}
}
}
}
}위 예시의 message는 멀티 필드로 이루어져 입력된 값을 standard 애널라이저와 english 애널라이저, nori_analyzer로 각각 색인해서 저장합니다.
reference
'🛠️TOOL > 🔭Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] - 인덱스 템플릿 사용하기 (0) | 2024.04.01 |
|---|---|
| [Elasticsearch] - 엘라스틱 서치의 색인 With 분석기 (1) | 2024.04.01 |
| [ELK] - 엘라스틱 서치란? (2) | 2024.03.27 |
| [Elasticsearch] - Elasticsearch의 각 노드 별 적정 메모리 할당 (0) | 2024.03.27 |
| [Elasticsearch] - 실제 배포 환경과 동일하게 멀티 노드 클러스터 구축하기 (2) | 2024.03.27 |
